I’m very familiar with the “people problem” to which you refer. Wind energy is normally done in remote areas where the wind blows and nobody wants to live. Why does nobody want to live there? Because it’s too windy! I once had a guy who declared in no uncertain terms he wanted to play a big role in my wind energy effort. He’d call me and talk for hours about all the things he would do, or could do. He’d keep coming up with titles reflecting his “future ccomplishments” with SuperTurbine™. “Head of Fabrication” sounded nice until we found out he was bothered by the sound of machinery, and not so good at designing and building things. The last “position” he tried to carve out for himself was to come up here to the Mojave Desert, and find a commercial building willing to let us build a wind energy system on the roof. This was before I relocated everything up here. He drove up here once or twice, poked round a bit, and, finally realizing the true nature of wind energy as a rural pursuit, he told me “There aren’t enough nice restaurants up there”, and decided he was better off developing electric trucks in a super-populated area, instead of wind energy in a remote location. Ironically, we’ve seen a multitude of new restaurants built up here in the last few years, since we are on the crest of the wave of development, near the 15 Freeway, that goes from L.A. to Las Vegas, in the vast open area that inspired the “Roadrunner” cartoons, where you can see for a hundred miles. People fly airplanes without a license up here, and there are dry lake beds where you can drive as fast as you want - no speed limit. Areas where there is nobody and nothing, as far as the eye can see. Now I thought this guy would be an electric-truck billionaire by now, but that fell apart too. Something about having to DO things rather than just talking about it comes into play at some point when developing new technologies. He raised money and got some of the first electric trucks onto the road, but seems unable to produce any more these days. I think what’s really going on here is something like this: people are very comfortable living in comfortable areas, comfortable saying “we will build this”, “we will solve that”, but the minute they see the reality of what they are facing, and all the hard work it entails, whether it is the development of the concept, the development of the actual product, the manufacturing and distribution of the product, or even just getting to a remote location required for testing, it’s too much for the people used to sitting in their comfortable chair, clicking on their smart-phone, taking selfies, having the internet and computer magically “solve” all their problems, because as long as they remain self-straight-jacketed in their padded-cell fantasy-world, where all accomplishments are hypothetical and “in the future”, they can find more computer-bound financial people to give them money. But the reality is nobody wants to bother even going to a place where they can freely develop airborne wind energy solutions, let alone actually moving there and doing it. Far easier to keep making excuses, issuing press-releases for every mundane event such as “renting office space”, while never getting out of the “comfort zone”, which would mean a bunch of guys out in the middle of nowhere, rolling up their sleeves and getting something working well on a daily basis. Forget it: no nice restaurants.
In the Fault Tree Analysis included in the document
Improving Reliability and Safety of Airborne Wind Energy Systems
The description of the most dangerous situation envisaged is
Kite is Outside of Operation Zone
That is what happened in this case.
But I don’t think that is the worst case scenario. An anchor dragging departure from the kite test zone is more scary… (whilst on fire beside a nuclear facility… yada …) Anchor dragging potentially enables a much further and ongoing interference zone and carries greater energy and solidity to a potential impact.
There may have been mitigation to prevent this outcome in the FMEA and in the build.
IMO, A single headed fault tree for a worst outcome event is not enough for a system design capable of such a complex failure set.
I’d love to hear more advice on the fully toggled control logic presented by Ampyx at AWEC
Answering Tallak about how AWES testing can coexist with populations, with low risk and low costs.
Multi-line soft-kites are safety and cost advantaged by many-connected “topological stability”, that can reliably self-kill within field-bounds when a primary line fails, plus soft-kites have inherently lower impact mass per unit-power, lower impact velocity, and lower capital cost. The chance of multi-lines all parting at once is ultra-low compared to single-line AWES vulnerability. Multi-lines also support control-actuation from the ground, eliminating com-link dependence and avoiding control-pod unreliability and excess-mass aloft.
Google can afford the high cost of safety-challenged high-complexity single-line prematurity. There is significant risk to Hawaiian third-parties and property by M600 crash impact forces and wildfire risk, but even multi-fatality liability cannot break Google’s bank. They should have chosen a cheaper less-populated, less-sensitive testing site to build flight hours.
Tragedy is a powerful driver of aviation safety design. The safest AWES architectures may be the only utility-market winners, by cost-effective insurability. The safest AWES will be the first to operate over populations just as most aviation does. That’s kPower’s long-game bet.
On re-read Improving Reliability and Safety of AirborneWind Energy Systems
I’m concerned how detectability is scored in the FMEA in the paper.
Most FMEA studies include Severity x Probablility x Detectability to give a risk priority number where detectability is 1= unmissable fault, 10= not detectable unpredictable fault
This paper, however, uses just S.P and detectability seems to be listed inside the S score with the onus of detection seemingly referring to the user/owner/client perception of value degrading… This scoring method would suggest an inversion of the detectability scoring factor.
I’m probably missing something… The paper isn’t just a market perception risk analysis… It’s meant as a prep for a week-long deployment .
In the following, we use failure mode and effect analysis(FMEA) together with fault tree analysis (FTA), to assess and systematically improve the reliability and safety of the technology development platform described in Section 2. As an integral part of the fault management strategy we propose a failure detection isolation and recovery (FDIR) system. The operation target for this reliability analysis is one week of flight without human intervention, except for launching and landing.
I can’t see where the potential faults, for each subsystem, then each component, are assessed for severity possibility and detectability.
The proposed mitigations do reduce the probability of the overall score of paths to the ultimate stated failure of the FTA but I think the FTA might be inherently missing basic fault modes.
OK … it can’t be the full company document for good reasons and this paper just shows an example of the analysis … the real company analysis held confidential IP and is duly not disclosed here…
The painstaking Ampyx approach to safe design paid off
The reason I’m focusing on this at the moment is that FMEA is basically a business process model … follow it and you should make cash or find ways to add value through mitigation improvements.
I’m developing an FMEA & FTA set in the run up to a 5kW Daisy system.
from a list of ~115 potential faults severity 1-9 possibility 1- 5 detectability 1- 5 our mitigations will reduce the total score of RPN (not a very indicative figure) from 4781 to 1780 ~= a 62.8% less risky venture.
If the VC’s could form an orderly queue to the left of the door and not annoy my neighbours while you wait please.
Ampyx’s high-velocity high-mass architecture must achieve < 1 major mishap per 100khrs to approach minimal aviation safety insurability standards. Its not clear what Ampyx data Rod is basing his conclusions on. If Ampyx made its Flight Logs public, there would likely not be very many hours between crashes, and no hours logged operating the AP3 from a catapult perch. All that “safety” is pure speculative marketing.
Kitepower is comparably exposed. Its Mishap Report and Fault Modes Analysis do not meet best-practice. The NASA Helios Mishap Report is the gold-standard, and Wubbo embodied NASA excellence while he lived. Sadly, the TUD venture circle spin-offs are poor AWES safety design models, from single-line to com-link dependence, and many known failure modes ignored.
Kitepower is currently withholding crash data on where its UHMWPE tether dragged and ended up, especially whether it draped across Valkenburg traffic and pedestrians. The safety reporting offered is very incomplete, and reflects venture capitalist self-interest more than sound aviation sector precedent.
On continued analysis, Kitepower’s AWES crash likely involved its long dragging tether snubbing-up in the urban fabric of Valkenburg; because a freely drifting kite/control-pod would be far less likely to develop enough kinetic energy to actually punch a hole in a commercial metal roof; a high force impact that could have been fatal to a pedestrian.
Aviation Mishap Reporting is not complete until all serious open questions are diligently addressed. AWE is supposed to be a self-regulating aviation sector, like all the others, collectively responsible for our safety culture. The Kitepower crash is not yet setting a satisfactory reporting precedent for AWE, consistent with established aviation norms.
There continues to be no answer to open tether disposition questions by Kitepower. Whether the tether draped across traffic lanes, or snubbed up on fixed objects, has general relevance to future AWE safety.
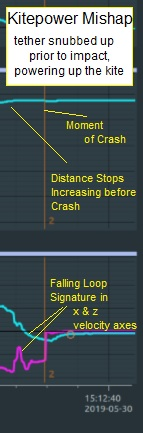
Data analysis shows that KitePower’s 60m2 kite did snub-up just prior to impact, which explains the high momentum that punctured the commercial roof. The kite was dangerously powered-up, not drifting down gently. Kitepower has not disclosed this key fact and is unresponsive to questions.
ISO9001 inquiry about Kitepower’s mis-management of its Mishap investigation has now led to TÜV Rheinland, as the controlling ISO authority. Does anyone but Luke think it wrong to seek withheld Kitepower Mishap data via the ISO overview process? There is no moral or technical case for not seeking full public disclosure and discussion of this historic precedent-setting AWES Mishap.
Which data are you looking at? My understanding was that the tether speed was reversed from full out to full in when reaching the end of the tether. So I would expect the kite to have been fully powered before somethibg else happened as a consequence
This became a kite breakaway/runaway event after software-failure and design-errors caused winch-failure. Kitepower has not disclosed information about supposed full-length tether dragging, so we must reason from scant clues and heuristic kite expertise.
Normally a runaway kite drifts down depowered, since the tether is no longer anchored. Its most dangerous if the tether drags massive hardware in sustained dragging, or catches on anything, recovering full power (mass x velocity). In this case the control pod actually punched a fairly big hole in in a supermarket roof, which a drifting kite alone would not do. The data seems to confirm the kite tether snubbed up hard right before impact.
Presumed accelerometer data from the same report linked before.
Once again, a high-risk AWES mode identified and discussed on the Old Forum, from historic to modern mishaps, that AWEurope’s circles never seem to have anticipated. Expect many more such previously documented AWES failure modes to haunt the ventures that did not pay attention.